Running SQL on Dynamo DB through Athena
Introduction
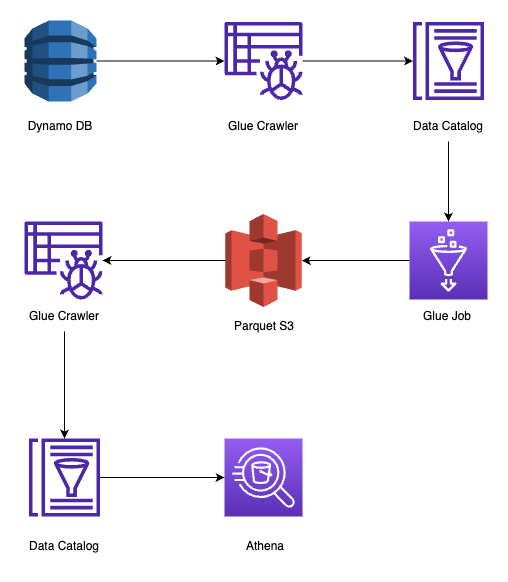
Athena is a service that allows you to run SQL queries on different data sources like Amazon S3. However Athena doesn’t support Dynamo DB as a data source. In order to circumvent this issue, we will use some of the glue services and store data in parquet format in S3.
Dynamo DB Crawler
A glue crawler is a tool to populate a Glue Data Catalog. An AWS glue data catalog is a database that can have multiple tables. Each table can have the schema or index of where and how data is stored in a particular data source. This data can be populated using a glue crawler.
- Configure a glue data catalog
CrawlerDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: DynamoDBCrawler
Description: Database for crawlerThe DatabaseInput field is to will be where the dynamo db schema will be stored. CatalogId is the AWS account id.
- Configure a Crawler for Dynamo DB
The role required can make use of AWSGlueServiceRole Managed Policy Arn with glue.amazonaws.com as principal. Other Permissions related to Dynamo DB include -
- GetItem
- Scan
- DescribeTable
- Query
DynamoDBCrawler:
Type: AWS::Glue::Crawler
Properties:
Name: dynamoDBCrawler
DatabaseName: // Name of glue data catalog database
Role: // Role with Dynamo DB and Glue Service Role
Targets:
DynamoDBTargets:
- Path: // Enter name of Dynamo DatabaseDefining the target of a crawler tells it which data source to crawl. On running, this will create a table with the same name as that of Dynamo DB.
Glue Job to update Data in parquet format
To deploy a glue job, it is imperative to write a python script to tell it what to do. Refer here : AWS Glue Tutorial Basically it can have three nodes. One dynamic node referencing data catalog database with the name of Dynamo Db. A second node to apply mapping. A third node to write it in parquet format. Learn more about parquet format here: Parquet.. This python script needs to be stored in a S3 bucket. This can be done through AWS console or as I prefer it using AWS CLI.
aws s3 cp filename.txt s3://bucket-nameAfter uploading the script to the bucket, you can reference it in the Glue Job like,
GlueJob:
Type: AWS::Glue::Job
Properties:
Name: // Job Name
GlueVersion: '3.0'
Command:
Name: glueetl
ScriptLocation: s3://script-location-glue/script.py
Role: // Role with S3 Read and write access and glue service roleThe Role should have a AWSGlueServiceRole and S3 Read and Write Access.
S3 Crawler
Once the Job is complete, we can use a crawler to define the schema in glue data catalog table. This table can be part of the same data catalog Database defined above for the dynamo db.
S3Crawler:
Type: AWS::Glue::Crawler
Properties:
Name: s3Crawler
DatabaseName: // Name of glue data catalog database
Role: // Role with Glue Service role and S3 access
Targets:
S3Targets:
- Path: // Name of S3 bucketStep Functions to run it all
Using Glue Jobs with step functions is pretty straightforward. AWS Step Functions will wait for the Glue Job to complete when you add ‘.sync’ to Resource section.
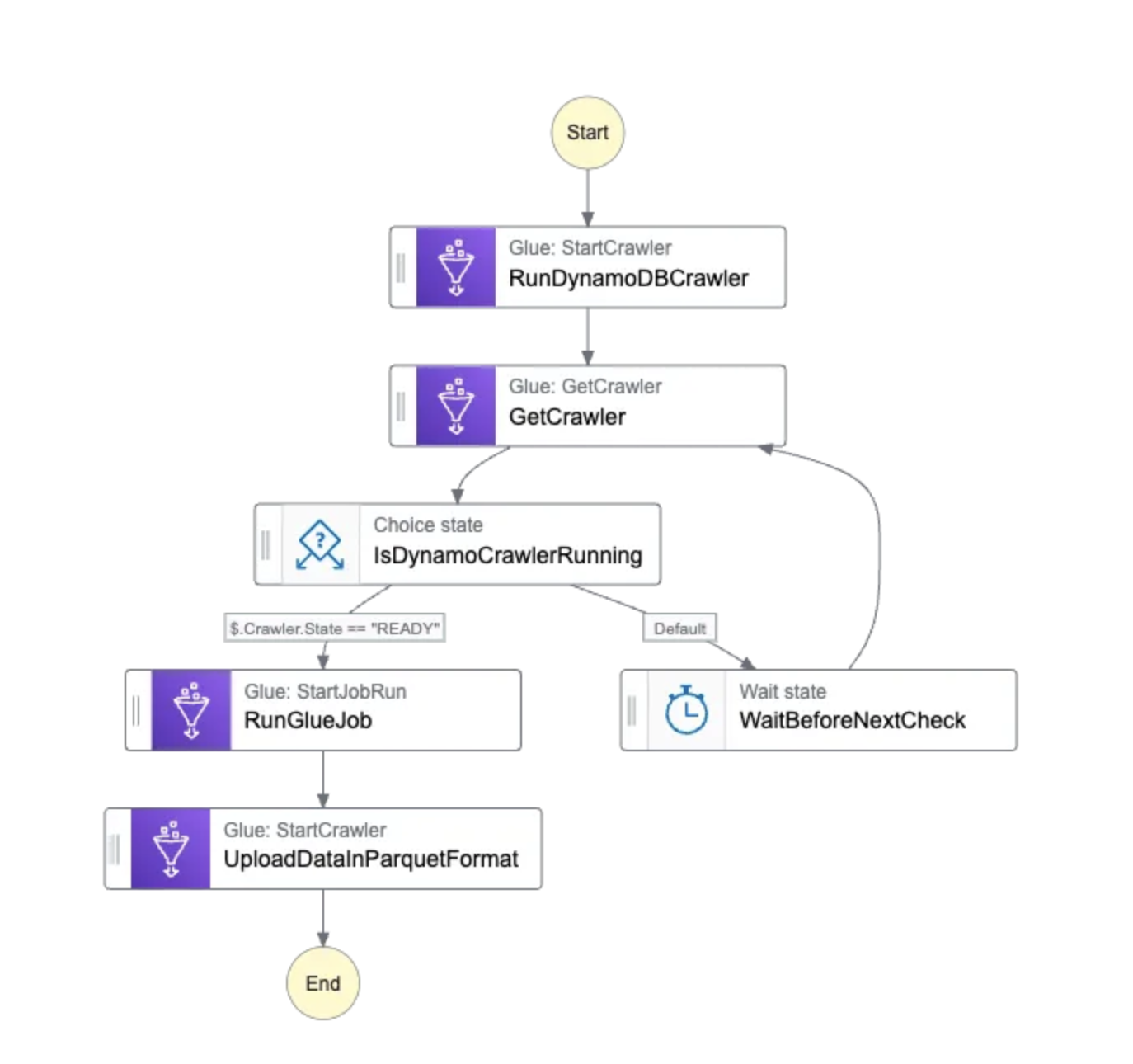
RunGlueJob:
Type: Task
Parameters:
JobName: !Ref GlueJob
Resource: arn:aws:states:::glue:startJobRun.sync
Next: UploadDataInParquetFormatHowever Running crawlers is not as straightforward. It will require adding a get crawler request and using a choice state to check whether the crawler is running or not. And crawler tasks are run through aws-sdk.
arn:aws:states:::aws-sdk:glue:getCrawlerThe Choice state can check for the variable $.Crawler.State for READY to see if the crawler has stopped running. Adding a wait and can help reduce unnecessary requests. After a workflow execution, you are good to run queries after selecting the name of the S3 bucket from the Athena console. Or you can use aws-sdk for Athena to run queries.